Googleドライブには、OCR(画像の文字認識)機能や翻訳機能があります。
#知らなかった (^_^;)
実用性があるかどうか、ためしてみました。
まずは、ためしたいファイルを、Googleドライブに保存しておきます。
対応するファイル形式は、jpg/png/gif/pdf。
PDFは、複数ページでもOK。
「ファイルサイズは2MB以下で、文字の高さは10ピクセル以上」という条件。
1.OCR機能
サンプルとして、「長文のレイアウトを考えよう(3)」の作品例を。

以下の3つを、用意しました。
(1)文字情報を残したままのPDFファイル
(2)各ページを画像化したPDFファイル
(3)各ページの画像ファイル(PNG形式)
使い方は・・・
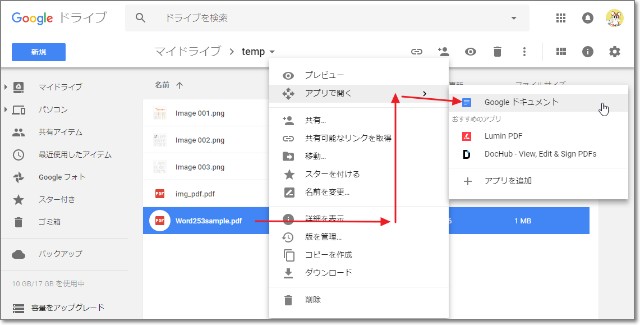
ファイルを右クリック→「アプリで開く」→「Googleドキュメント」 とするだけ。
結果は・・・
(1)は「文字を認識できて当然」のはずですが、書式がグチャグチャでした。
(2)は、白紙状態。
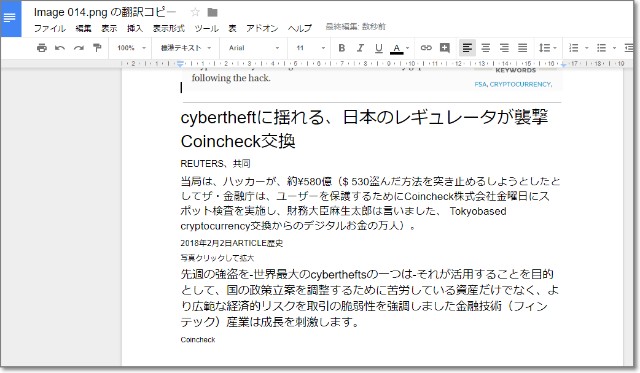
(3)がいちばんまともでしたが、それでも下図のようなありさま。
「縦書き」や「段組み」がいけないのでは。
・・・ということで、ごくふつうの横書き文書にして、再チャレンジ。

結果は・・・
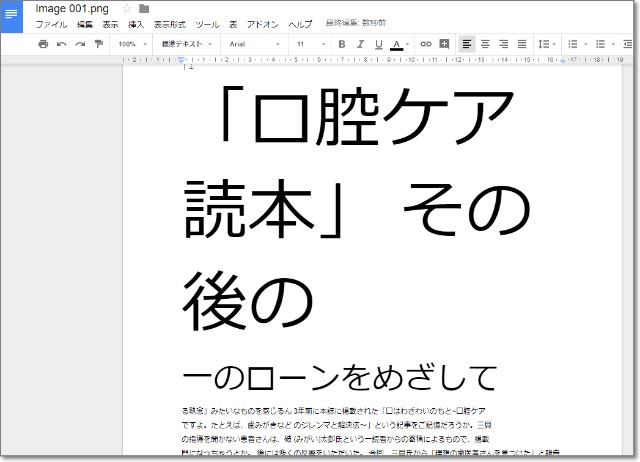
(1)は、当然のように100点。
(2)は、やはり白紙状態。
(3)は、画像の下にOCR結果が表示されています。
なんと、100点満点!
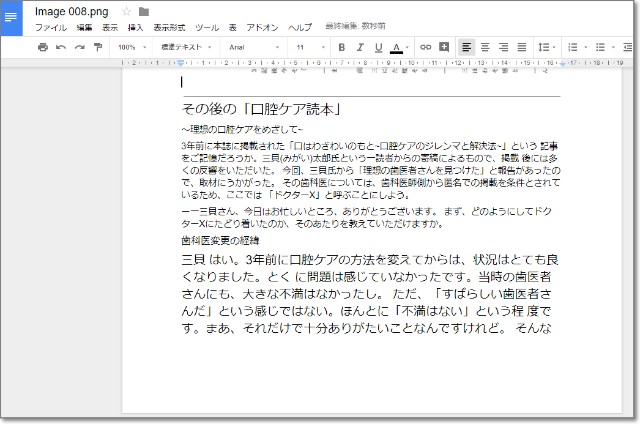
結果は・・・
他にもいくつかためしてみましたが、
書式がノーマルなものは、バッチリ実用性があります。
画像化されているPDFファイルは、まったく対応していないようです。
用紙をスキャナで読み取ったものは、ダメかも。
縦書きは、画像ファイルはうまくいきますが、なぜかPDFファイルは文章が乱れます。
段組みは、PDFファイルはバッチリですが、画像ファイルは文章が乱れます(当然かな)。
縦書き&段組みの場合は、かなり厳しい。
2.翻訳機能
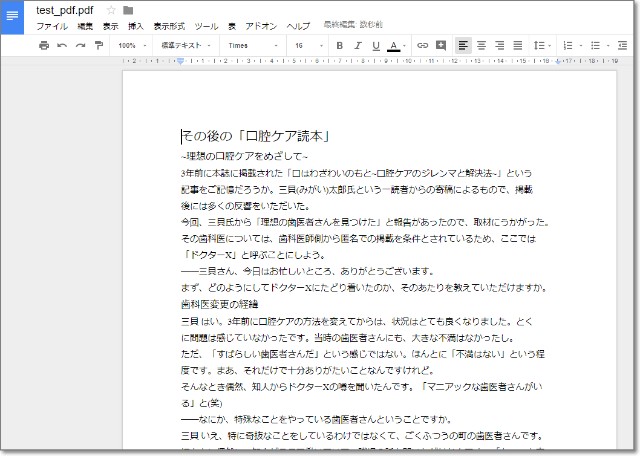
The Japan Timesの記事を、キャプチャして使用してみます。

1のOCR機能を使うと、右カラムがちょっと間に入ってしまいますが、ほぼ100点。
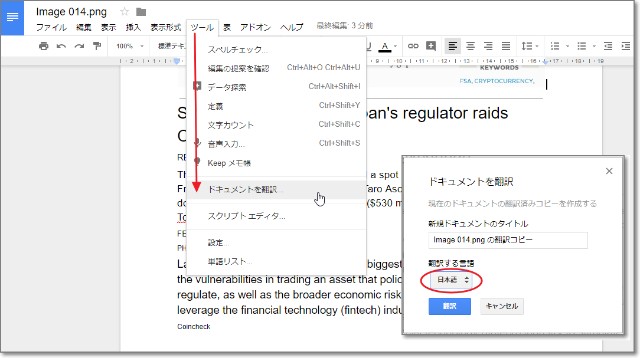
Googleドキュメント化した状態で、「ツール」メニュー→「ドキュメントを翻訳」。
翻訳する言語を指定して、「翻訳」ボタンをクリックすると・・・
ちゃんと、Google翻訳レベルで翻訳してくれます。
cybertheft(サイバー泥棒)は、まだ辞書にないようです。